검색엔진최적화(SEO), URL, HTTP, 크롤링?
S : search
E : engine
O : optimization
정보 · 통신 검색 엔진에서 검색을 했을 때, 웹 페이지가 상위에 나타나도록 하는 일. 핵심 키워드를 선택하여 사이트를 등록할 때 사용하고 배너 교환이나 추천 사이트 등록을 이용하면, 이용자가 늘어나면서 사이트의 순위도 올라가게 된다.
시대가 너무나 많이 변하고 달라졌다. 빠르고 어렵고 취향도 제각각이고 모르는 분야도 일단 너무나 많다. 그냥 단순히 글이 쓰고 싶어 시작한 일이 점점 노동이 되어가는 중이다. 10여년 전에 자잘구레한 내 일상글을 올리고 이웃들과 소통하고 구독자가 늘어가는 것이 재미가 있어서 밤잠을 잊고 써 댔던 기억이 나서 요즘 다시 지난 일들을 기록하고 주변에 일어나는 관심꺼리들을 쓰면서 취미삼아 시작한 일이 어느덧 내 발목을 잡고 있다.
원래 뭘 시작하면 끝장을 보는 타입인데 이젠 나이가 나이인지라 적당하게 대충 즐기면서 하는 뭔가를 찾다가 동영상 유튜브를 보면서 다육이에 빠졌는데 다육이 키우는 유튜버들이 하도 실력도 쟁쟁하고 무엇보다 화원을 경영하시는 분들이 대거 포진해 있어서 아무리 취미생활로 시작한 다육생활이지만 남들에게 보여주기에는 무리가 있었다. 그래서 옛날에 끄적이던 글방을 먼지털어 햇살 창가에 내놓고 정비하던 중이었는데 예전과 다른 뭔가가 많이 바뀌었다.
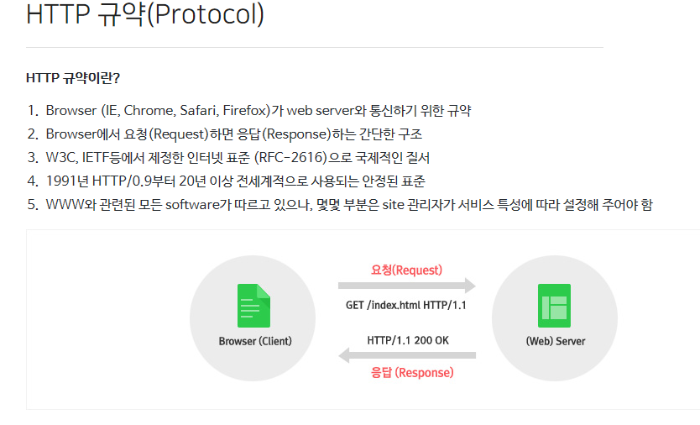
URL - uniform resource locator
인터넷에 존재하는 수많은 정보 자원의 위치를 정확하고 편리하게 표현하기 위한 방법. 인터넷의 크기가 점점 커지면서 특정 정보가 인터넷 상의 어디에 있는지를 나타내는 효율적인 방법이 필요하게 되었는데 그 중 URL이 가장 널리 사용되고 있다. URL의 형식은 다음과 같다.
프로토콜://서버주소/정보의 경로
첫째, 프로토콜이란 어떤 방법으로 원하는 정보에 접근할 것인가를 나타내는 부분으로 월드 와이드 웹의 경우 http를 사용하며 ftp, news, gopher 등이 프로토콜 자리에 들어간다.
둘째, 서버주소란 해당 정보가 어떤 컴퓨터에 위치하고 있는지 알려주는 것으로 도메인 네임이나 IP주소로 표시된다.
셋쩨, 그리고 정보의 경로는 해당 정보가 그 컴퓨터의 어느 곳에 있는지를 알려 준다.
유튜브 고수님들의 강의를 듣다보면 알 수도 없는 단어들이 너무 많았다. 그리고 해야 할 것과 하지 말아야 할 것도 너무나 많아서 정작 진짜 알맹이인 글 자체를 쓰는 것보다 전체적인 테두리, 느낌, 사진 등 이런 외적인 것들을 챙기는게 너무 시간이 많이 빼앗기는 느낌이다. 그러나 시대가 변했고 흐름을 따라야 하니 어쩔 수 없어서 노력은 하고 있지만 웬지 주객이 바뀐 것 같은 서글픔이 존재한다,
내가 만든 컨텐츠가 검색결과에 노출되도록 방문자가 많아져서 뭐가 좋은지는 모르겠지만 구독자가 생기는 것도 아니고 어떤 날은 조회 및 방문자가 천명이 넘다가 어떤 날은 4백명이었다가 들쭉 날쭉 한 것이 영 마뜩찮다. 그래서 검색엔진이 뭐냐? 검색엔진의 최적화는 또 뭐냐? 를 찾아나섰다.
검색엔진 최적화의 목적
검색엔진 최적화 작업은 사이트 내 콘텐츠 정보를 검색엔진이 잘 이해할 수 있도록 정리하는 작업입니다. 이 작업을 통하여 사이트 내 콘텐츠가 네이버의 검색 결과에 누락되지 않도록 조치할 수 있으며, 무엇보다 사용자가 원하는 콘텐츠의 내용을 명확하게 네이버 검색엔진에게 알려 줄 수 있습니다.
네이버 검색은 검색엔진에 친화적인 사이트를 우대합니다. 여러분의 사이트가 검색엔진에 최적화되어 있는지 본 가이드를 꼼꼼히 읽어보고 점검해보세요. 네이버 검색과 웹마스터도구가 여러분 사이트의 방문자 유입이 증가될 수 있도록 도와드리겠습니다.
네이버 웹마스터도구 ==> 네이버 서치어드바이저 searchadvisor.naver.com
네이버 서치어드바이저를 열고 나의 블로그 URL주소를 등록하기
구글 서치 콘솔 Google Search Console ==> https://search.google.com/search-console/about?hl=ko
구글 사이트에 내 블로그 등록하기, 웹 크롤링, 색인 생성 관리 도구, 사용자 링크, 검색어 트래픽 등 정보 제공.
블로그 차트 가입하고 순위 알아보기 www.blogchart.co.kr/
내 블로그를 분석하고 순위도 알아보고 유효키워드는 몇 개나 되는지 알아보았습니다. 하지만 굳이 그럴 필요가 있을까 싶지만 혹시 필요하신 분들은 위 사이트를 방문하셔서 일단 가입하면 대충은 볼 수 있고 그 다음 상세한 것은 유료로 가입을 해야 하는데요. 매월 금액이 10만원대 되는 걸로 보이던데 글쎄요. 필요없을 것 같아요. 내 글이 노출이 되고 안되고는 내 맘대로 되는것이 아닌 것 같은데 디지털 노마드를 자청하는 고수님들의 이야기는 참 꿀맛같은 딴 나라 이야기를 많이 하신다.

검색 로봇 수집
*검색 로봇 수집과 관련된 대표 품질 항목은 로봇룰 설정에 따른 수집 가능한 문서의 양과 올바른 XML 사이트맵과 RSS의 존재하는지 여부입니다.
* 네이버 검색결과에 노출되는 사이트의 콘텐츠는 검색로봇이 사이트를 방문하여 정보를 수집, 색인과정을 처리한 뒤 로직에 따라서 반영됩니다. 그러므로 외부 사용자에게 허용할 수 있는 콘텐츠에 대하여 네이버 검색로봇이 여러분의 사이트를 인지하고 수집할 수 있도록 웹 표준으로 지정된 로봇룰을 올바르게 지정할 필요가 있습니다. 내 사이트 내에서 검색에 노출할 대상인 콘텐츠와 비 노출할 콘텐츠를 분류하여 로봇룰을 작성하는 것이 매우 중요합니다.
*웹 상에서는 수억 개의 사이트가 존재하며 네이버 검색로봇이 모든 사이트의 콘텐츠를 빠른 시간내에 방문하기에는 한계가 있습니다. 사이트 내에 수집되어야할 페이지들을 네이버 검색 로봇에게 알려 줄 있는 XML 사이트맵은 검색 로봇의 수집을 도와줄 수 있는 유용한 방법입니다. 또한, 사이트 내에서 새로 생성된 신규 글에 대하여 웹 표준인 RSS 를 이용한다면 최신 콘텐츠의 검색반영을 보다 빠르게 검색로봇에게 알려줄 수 있습니다.
[ search robot ]
요약 검색엔진이 검색 데이터베이스의 내용을 보충하기 위해, 웹페이지를 검색하여 가져오는 프로그램을 말한다.
전문검색형(全文檢索形) 검색엔진의 데이터베이스를 작성하기 위하여 웹페이지를 가져오는 프로그램이다. 검색 데이터베이스의 내용을 충실하게 보충하거나 이를 점검하는 역할을 한다.
전문검색형 검색엔진에서는 웹페이지의 내용을 검색엔진 쪽의 데이터베이스에 보관하고 있다가 검색 요청이 있을 때는 그 데이터베이스를 검색하여 결과를 꺼내 보여준다. 검색로봇은 이 데이터베이스에 수록되어 있지 않은 웹페이지나 갱신된 웹페이지를 찾아내 그 결과를 데이터베이스에 반영시킨다.
검색로봇이 웹페이지를 찾아내는 수단이나 검색의 대상으로 삼는 파일의 종류는 여러 가지이다. 검색로봇에 따라서는 텍스트파일이나 PDF파일, 엑셀이나 워드프로세서 등으로 작성한 문서 파일도 가져간다. 이 때문에 접속할 수 있는 권한을 제대로 설정해 놓지 않아 기업의 기밀문서가 노출되는 경우도 있다.
검색로봇에 의해 검색되지 않기를 원하는 파일은 이를 저장할 때 HTML파일 내에 검색을 거부하는 것을 명시한 메타태그(META TAG)를 기입하거나 웹 서버의 공개 디렉터리 최상층에 로봇의 거동을 지정하는 파일을 배치하는 방법이 있다.
그러나 검색로봇에 따라서는 이와 같은 지정을 무시하고 파일을 가져가는 경우도 있기 때문에 고도의 기밀성이 요구되는 파일은 접속권한을 제한하는 등의 방법을 사용한다. [네이버 지식백과] 검색로봇 [search robot] (두산백과)
크롤링[ crawling ]
무수히 많은 컴퓨터에 분산 저장되어 있는 문서를 수집하여 검색 대상의 색인으로 포함시키는 기술. 어느 부류의 기술을 얼마나 빨리 검색 대상에 포함시키냐 하는 것이 우위를 결정하는 요소로서 최근 웹 검색의 중요성에 따라 발전되고 있다. [네이버 지식백과] 크롤링 [crawling] (IT용어사전, 한국정보통신기술협회)
웹 크롤러(web crawler)는 조직적, 자동화된 방법으로 월드 와이드 웹을 탐색하는 컴퓨터 프로그램이다.
웹 크롤러가 하는 작업을 '웹 크롤링'(web crawling) 혹은 '스파이더링'(spidering)이라 부른다. 검색 엔진과 같은 여러 사이트에서는 데이터의 최신 상태 유지를 위해 웹 크롤링한다. 웹 크롤러는 대체로 방문한 사이트의 모든 페이지의 복사본을 생성하는 데 사용되며, 검색 엔진은 이렇게 생성된 페이지를 보다 빠른 검색을 위해 인덱싱한다. 또한 크롤러는 링크 체크나 HTML 코드 검증과 같은 웹 사이트의 자동 유지 관리 작업을 위해 사용되기도 하며, 자동 이메일 수집과 같은 웹 페이지의 특정 형태의 정보를 수집하는 데도 사용된다.
웹 크롤러는 봇이나 소프트웨어 에이전트의 한 형태이다. 웹 크롤러는 대개 시드(seeds)라고 불리는 URL 리스트에서부터 시작하는데, 페이지의 모든 하이퍼링크를 인식하여 URL 리스트를 갱신한다. 갱신된 URL 리스트는 재귀적으로 다시 방문한다.
'알림마당 & 정보나눔 > 배우고 나누는 정보' 카테고리의 다른 글
| 개인정보수집, 사생활이 사라지고있다 (0) | 2020.05.23 |
|---|---|
| 사이트맵 (Sitemap.xml) 제출하는 법* (1) | 2020.05.22 |
| 민식이법 때문에 체크해야 할 것들 (0) | 2020.05.08 |
| 중소기업 · 소상공인 확인서 발급받는 방법-중소벤처 24 통합서비스 (0) | 2020.05.08 |
| 교통범칙금, 과태료 등 바뀐 법안들 알아보기 (0) | 2020.05.07 |




댓글